

OUR THOUGHTSAI
How to build an AI code copilot that responds with your own code
Posted by Tony Luisi . Dec 16.24
AI coding assistants and copilots continue to evolve and become more useful, reshaping the industry and changing the skills developers need to be productive. While these tools can be helpful, they also currently come with a significant drawback – they’re trained on a vast number of repositories of average code. The code they suggest reflects the quality of all the code they’ve been trained on, including excellent and problematic patterns.
What if, instead of getting suggestions based on average internet code, you could get recommendations based on the context of your organisation, its best and most relevant architectures and carefully curated patterns? This is why we explored building our own AI code copilot. While the copilot we describe here still needs some improvements before we use it day- to-day, we thought we’d share what we’ve learnt so it can help others exploring this path.
Teams often have their own way of doing things – specific architectural patterns, coding standards and practices that have evolved to solve their unique challenges. Traditional AI coding assistants might suggest solutions that, while technically correct, don’t align with these established patterns. Or perhaps you are deliberately trying to improve your current patterns and need to ensure recommendations reflect the future direction of travel. Either way, the benefits of using curated reference examples are significant.
Enter Retrieval Augmented Generation (RAG), a technique that allows us to combine the power of Large Language Models (LLMs) with a curated codebase. Instead of relying solely on an LLM’s training data, we can augment its responses with specific examples from our reference architecture and best practices.
The benefits include:
- Suggestions aligned with your organisation’s patterns and practices
- Code examples that reflect your specific context and domain
- Reduced risk of introducing inconsistent patterns
- Ability to keep sensitive code private by running models locally
In this article, we explore how to build such a system, breaking down the process into distinct phases – question optimisation, context retrieval and response generation.
How to optimise the question
The first challenge in building an effective code copilot is understanding what the developer is asking. Raw questions often lack context or specificity which can lead to suboptimal responses. This is where question optimisation comes in.
The question optimisation process
Refining the initial query involves using an LLM to transform the original question into something more precise and actionable. Here’s how it works:
Initial Query Processing: When a developer asks a question like “How do I create a root aggregate?”, we first pass this through an LLM with specific instructions to rephrase it as a standalone question that captures all necessary context.
Context Preservation: If this question is part of an ongoing conversation, we maintain a conversation ID and include relevant previous context. This helps ensure that follow-up questions maintain their proper context.
Token Management: In the next part of the process, when we retrieve the code example, we will provide additional context. The size of the additional context is measured by counting the number of tokens in the context. LLMs have token limits, so we need to actively reduce the scope of the questions we ask to ensure we stay within token limits. The question optimisation phase helps us manage token limits by creating concise, focused queries before we start adding additional context.
The key prompt instruction to the LLM at this stage is:
“Given the following conversation about a code base and a follow-up question, rephrase the follow-up question to be a standalone question”.
This optimisation step is important because it helps bridge the gap between how developers naturally ask questions and the kind of specific queries that work best with vector databases that we use to store our reference code patterns.
Getting the code example
Once we have an optimised question, we can start the process of retrieving and generating relevant code examples. This involves several key components working together.
Setting up the vector database
The foundation of our system is a vector database containing our reference code. Vector databases store software code by first breaking it down into meaningful pieces like functions and variable names through specialised parsers. These code fragments are then transformed into mathematical vectors using models that understand programming languages. The resulting vectors capture the structure and meaning of the code, with each dimension of the vector representing different aspects like syntax patterns or semantic relationships. These vectors are then stored in a specialised vector database, optimised for working with high-dimensional data. When you want to find similar code or search for specific functionality, the database can quickly compare these vectors using mathematical similarity measures. This vector-based approach makes it possible to find related code snippets even when the actual text of the code looks quite different since the vectors capture the underlying meaning and patterns rather than just matching exact text.
Here’s how we built ours:
Code Chunking: Firstly, we need to break down our reference codebase into meaningful chunks. Using LangChain’s utilities, we can split TypeScript/JavaScript files by function or class boundaries. This granular splitting ensures we can retrieve precisely relevant code segments:


Embedding Generation and Storage: We use OpenAI’s embedding model to create vector representations of our code chunks. These vectors capture the semantic meaning of the code making it possible to find relevant examples based on natural language queries. The code is then stored in ChromaDB with metadata preserved:


The retrieval process
With our vector database in place, let’s explore how the retrieval process works…
Our retrieval process consists of three main stages:
Vector Search: The first step involves converting questions into vector representations that can be searched against our codebase. Here’s how we implemented the vector store:


We use Chroma as our vector database and OpenAI’s embeddings to convert text into vector representations. The retriever then handles the actual search:

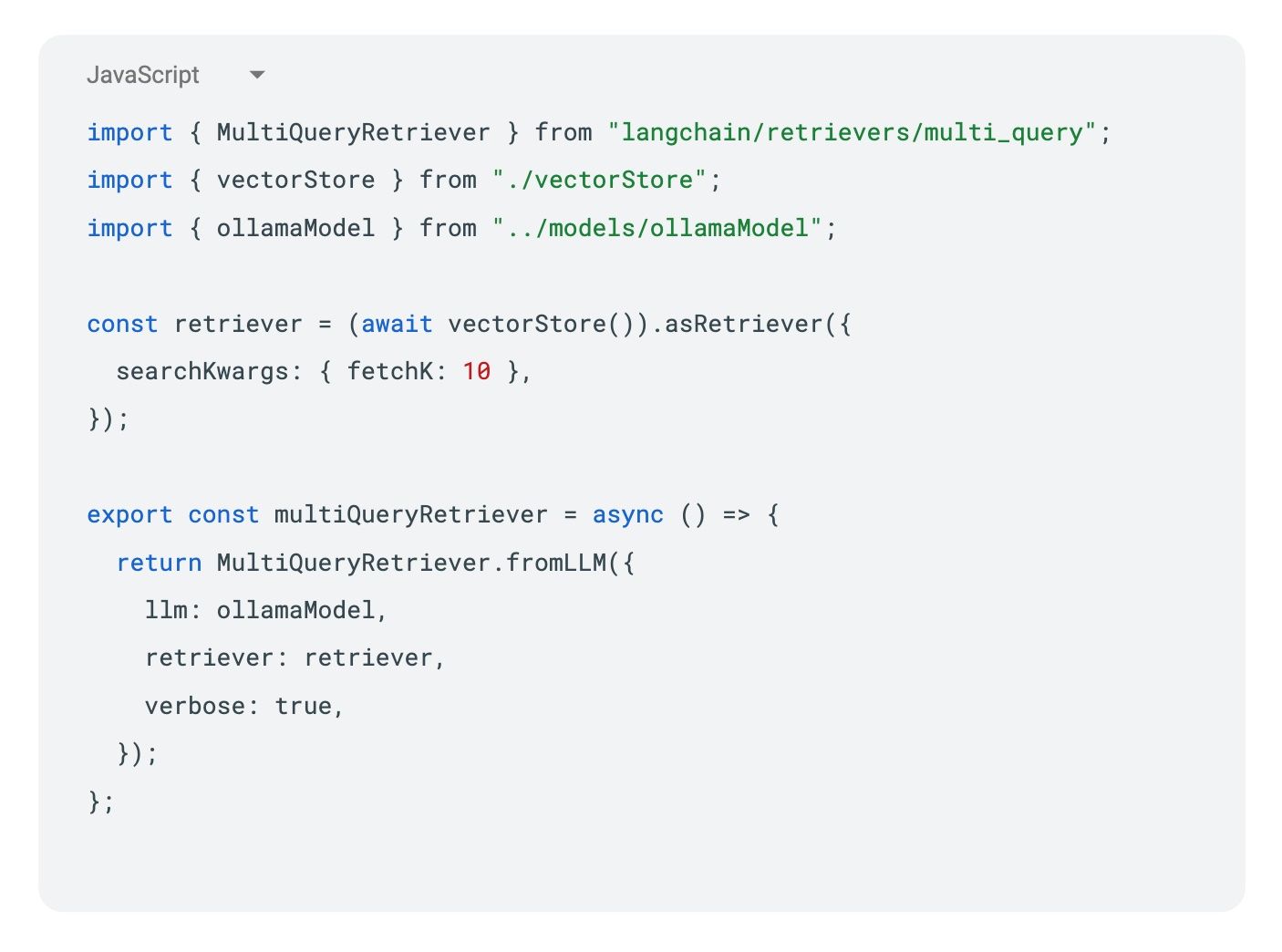
Context Assembly: Once we’ve found relevant code chunks, we assemble them with their context. Test files are particularly valuable here as they provide both code examples and natural language descriptions. Our combined documents chain handles this assembly:


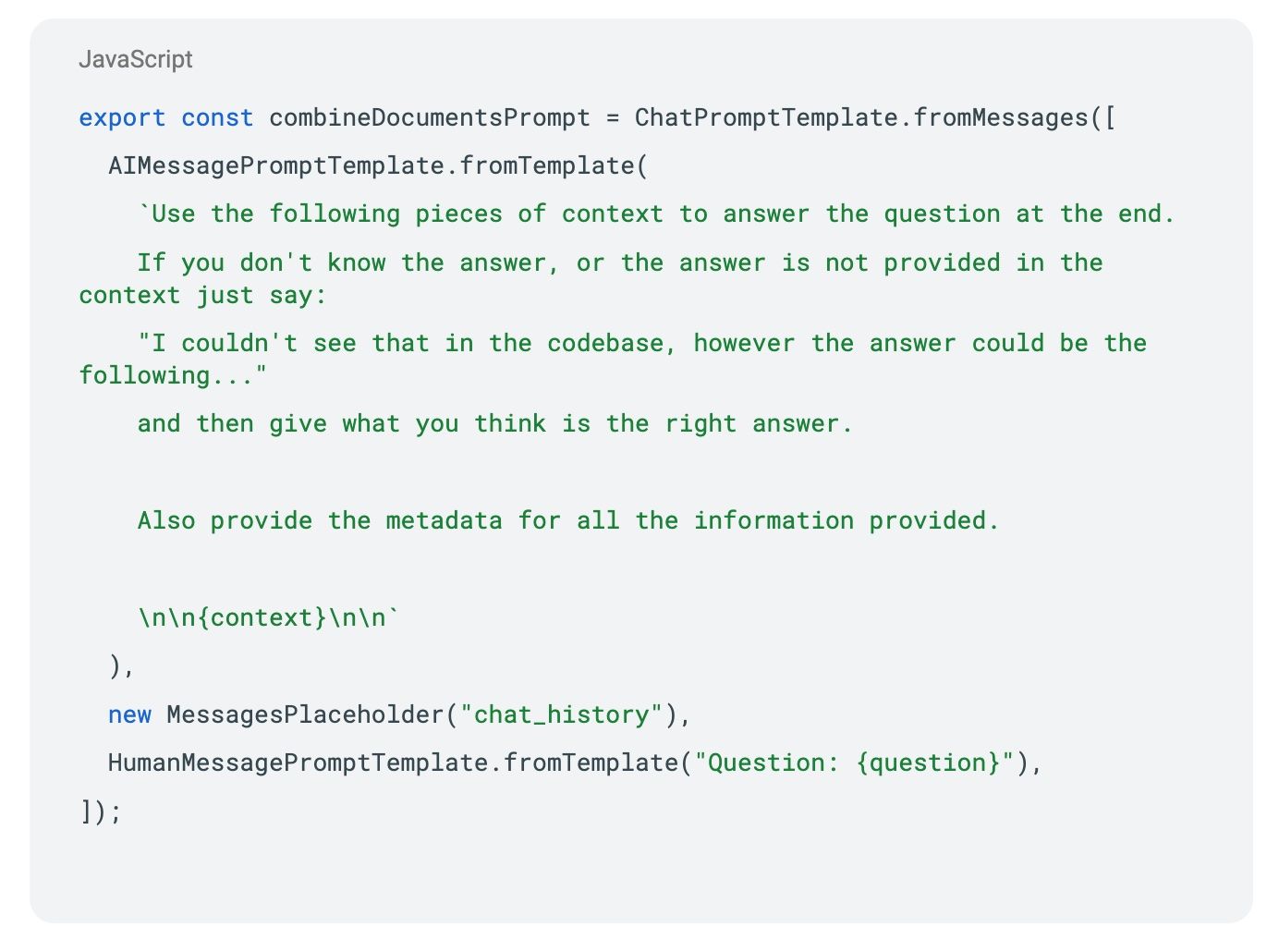
Prompt Construction: The final stage involves constructing a careful prompt for the LLM. Our prompt template ensures comprehensive responses:

The Complete Pipeline: All these components come together in our conversational QA chain:


When constructing the prompt for the LLM, we need to be very specific about what we want. Let’s break down each component in detail.
The optimised question is the foundation of our prompt. We begin by including the refined version of the user’s question that emerged from the question optimisation phase, making sure to maintain any relevant context from previous conversation turns. For instance, instead of a simple “How do I create a root aggregate?”, we might use “How do I implement a root aggregate pattern in TypeScript, considering any previous domain context from our conversation?”. This more specific framing helps the LLM understand the full context of the request.
Next, we incorporate retrieved code examples from our vector database. These should preserve all formatting and comments from the original code, along with sufficient surrounding context that helps understand the code’s purpose. When showing how to create a root aggregate, for example, we’d include not just the class definition but also any relevant factory methods or interfaces it implements. This comprehensive context helps the LLM understand how the code fits into the larger system.
Usage contexts form another crucial component of our prompt. We need to include real examples of how the code is used in production scenarios, along with test cases that demonstrate the code in action. We should also provide any domain-specific considerations. For instance, we might explain how a root aggregate is used in the OrderProcessing domain, including how it handles order items and validation. These concrete examples help ground the LLM’s responses in practical applications.
Instructions for referencing specific files and locations come next. We direct the LLM to mention the exact file paths where code examples come from, ask for references to specific line numbers or functions when relevant and request citations of test files that demonstrate usage. A good example would be asking the LLM to reference specific files like “This pattern is demonstrated in src/domain/orderAggregate.ts”. This specificity helps developers easily locate and understand the referenced code.
Finally, we provide guidance about admitting knowledge gaps. We explicitly instruct the LLM to acknowledge when it doesn’t have enough context and ask it to suggest reasonable alternatives when exact matches aren’t found. The LLM should clearly differentiate between what’s in the codebase and what’s being suggested. For example, if it can’t find an exact match for a pattern in the provided context, it should say so clearly but suggest an implementation based on similar patterns it’s seen in the codebase.
The resulting prompt combines all these elements into a coherent whole that guides the LLM to provide responses that are helpful and grounded in your actual codebase. This careful prompt construction ensures that the LLM stays focused on your established patterns and practices while maintaining transparency about the source and reliability of its suggestions. By providing this level of detail and structure in the prompt, we help ensure that the LLM’s responses will be more consistent, accurate and useful for your development team.
The result is a system that provides code suggestions in a way that maintains traceability back to your reference architecture while being honest about any gaps or assumptions in its recommendations. This approach helps developers trust and verify the suggestions they receive, making the tool more valuable for real-world development work.
Generating the response
The final step is generating a helpful response. In our instructions to the LLM, we ask it to craft responses that draw from the provided context to answer the question comprehensively. Each response should incorporate relevant code examples that demonstrate the solution in practice. The LLM must reference specific files from the codebase to help developers locate and understand the patterns being discussed. We also instruct it to be transparent about knowledge gaps, acknowledging when certain information isn’t available in the provided context. This honesty helps maintain trust in the system. Finally, the LLM should provide implementation suggestions based on actual usage patterns found in the codebase, ensuring that its recommendations align with real-world practices rather than theoretical solutions.
A crucial instruction to the LLM is: “Use the following pieces of context to answer the question at the end. If you don’t know the answer or the answer is not provided in the context, just say, ‘I couldn’t see that in the code base.’ However, the answer could be the following...”
Building your own AI code copilot using RAG offers a way to leverage AI while maintaining control over the quality and consistency of suggestions. While it requires more setup than using off-the-shelf solutions, the benefits of getting recommendations based on your organisation’s best practices are substantial.
While current AI tools may be over-stating their ability to write high-quality maintainable code without human input, they can be effective in accelerating work undertaken by people. By building a copilot that knows your codebase and patterns, you can create a tool that truly enhances developer productivity while maintaining the quality standards your organisation has worked hard to establish.


More
Ideas
our thoughts
Balancing the agentic innovation opportunity with security
Posted by Tom Lahoud . Mar 30.26
The Artificial Intelligence landscape is evolving at breakneck speed with organisations across Australia and New Zealand grappling with a fundamental challenge: how to harness the innovative potential of AI agents while maintaining robust security standards.
> Readour thoughts
Why software teams are shrinking to three people
Posted by Gareth Evans . Feb 23.26
Software teams are shrinking. Not because organisations are cutting headcount for its own sake but because AI agents are absorbing work that used to require five, seven or ten people to negotiate interfaces and split stories. The emerging unit is three humans and a constellation of agents.
> Readour thoughts
Data and analytics: are you asking the right questions?
Posted by Brian Lambert . Feb 09.26
The conversation around Artificial Intelligence in enterprise settings often focuses on the technology itself – the models, capabilities, impressive demonstrations. However, the real question organisations should be asking is not whether AI is powerful, but whether they are prepared to harness that power effectively.
> Readour thoughts
The future of voice intelligence
Posted by Sam Ziegler . Feb 01.26
The intersection of Artificial Intelligence and voice technology has opened fascinating possibilities for understanding human characteristics through audio alone. When we hear someone speak on the phone, we naturally form impressions about their age, gender and other attributes based solely on their voice.
> Readour thoughts
Is AI the golden age for technologists?
Posted by The HYPR Team . Oct 27.25
The technology landscape is experiencing a profound change that extends beyond the capabilities of Artificial Intelligence tools. We’re witnessing a fundamental shift in how people engage with technology, build software and think about their careers in the digital space. This shift raises a compelling question... Are we entering a golden age for technologists?
> Read